Study Design
Participants wrote a 30-minute argumentative essay using a custom interface with an embedded LLM assistant.
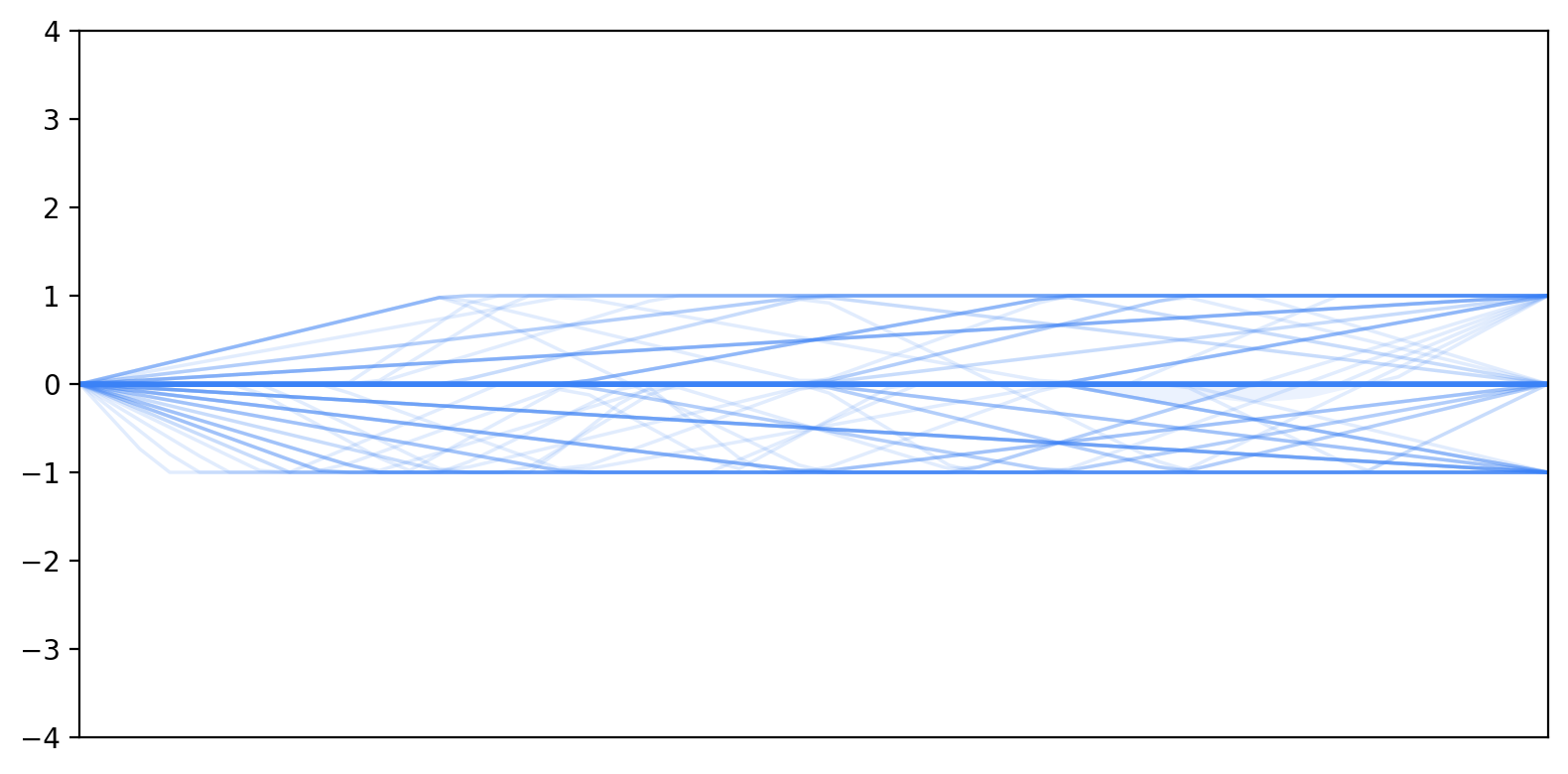
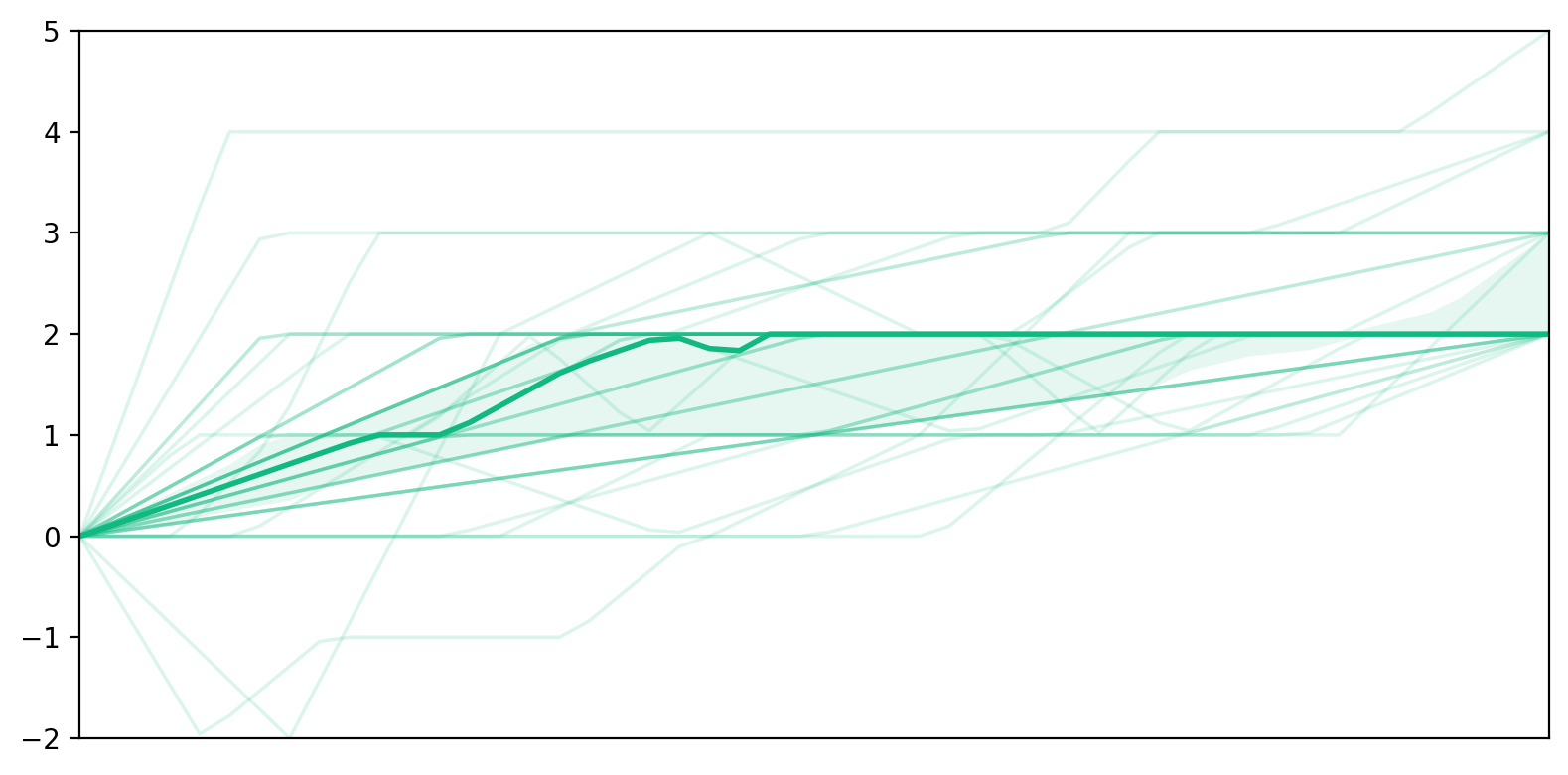
Before sending a new prompt, participants rated their current momentary self-efficacy and trust on a 7-point Likert scale, allowing us to track their trajectories across each interaction turn.
Self-Efficacy
User’s momentary belief in their ability to complete this task on their own.
Trust
User's momentary belief that the LLM will reliably support this task.
Key Findings
🔄 Diverging Dynamics of Self-Efficacy and Trust
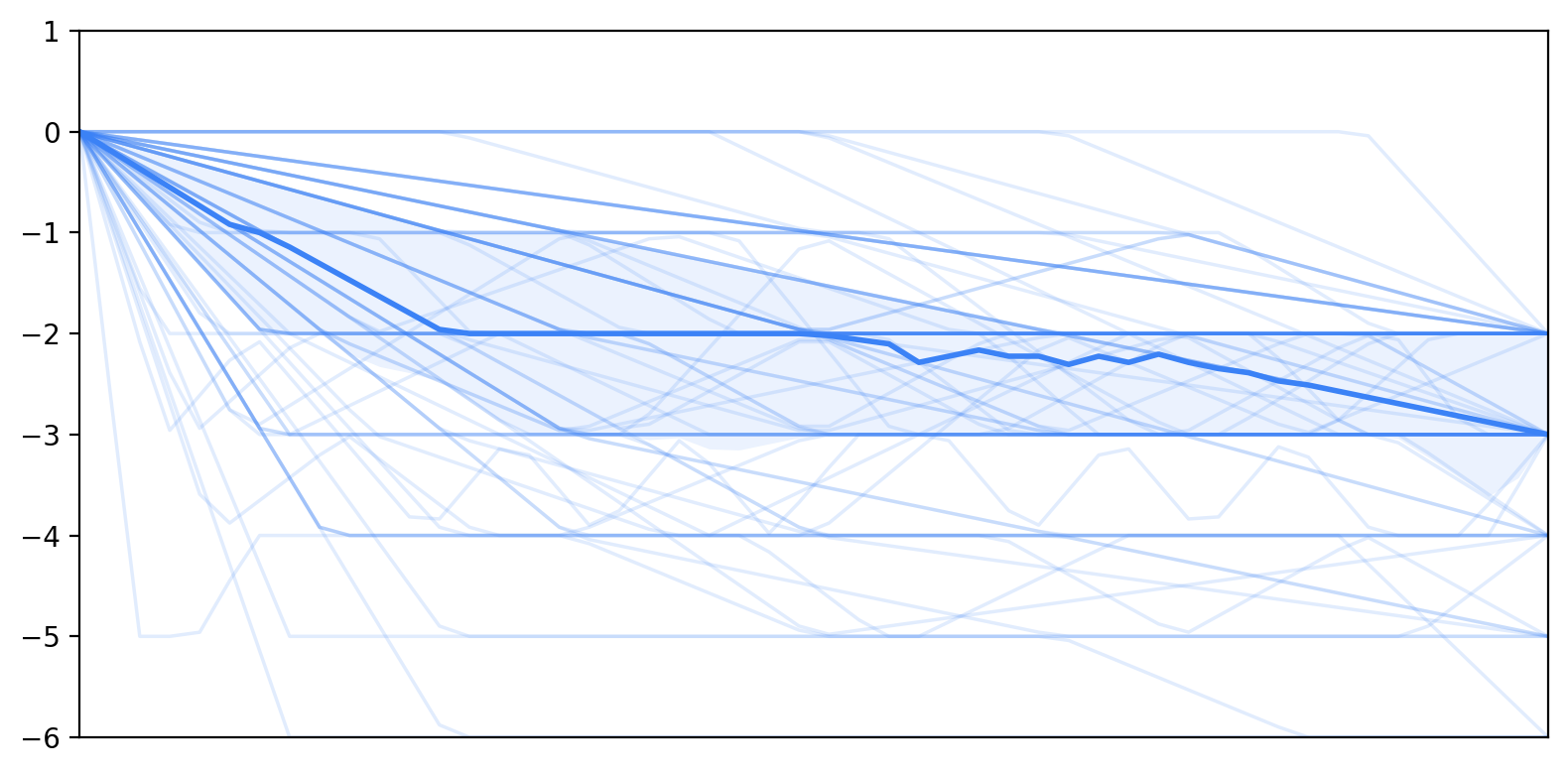
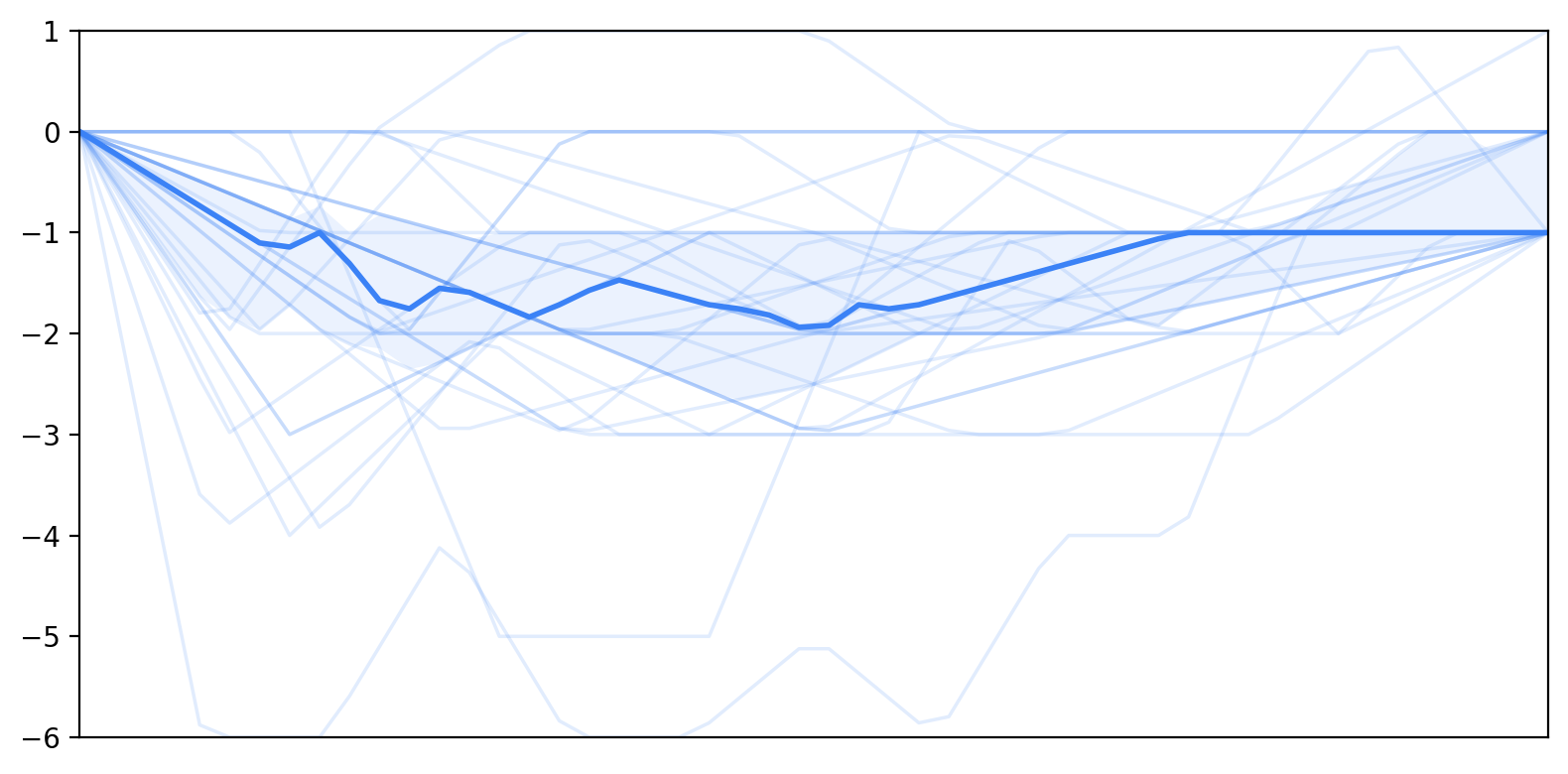
Self-efficacy declined across interaction turns while trust increased.
Self-efficacy trajectories began at similar initial levels, and trust acted as a buffer against declines in self-efficacy.
💬 Self-Efficacy and Trust Trajectories in Prompting
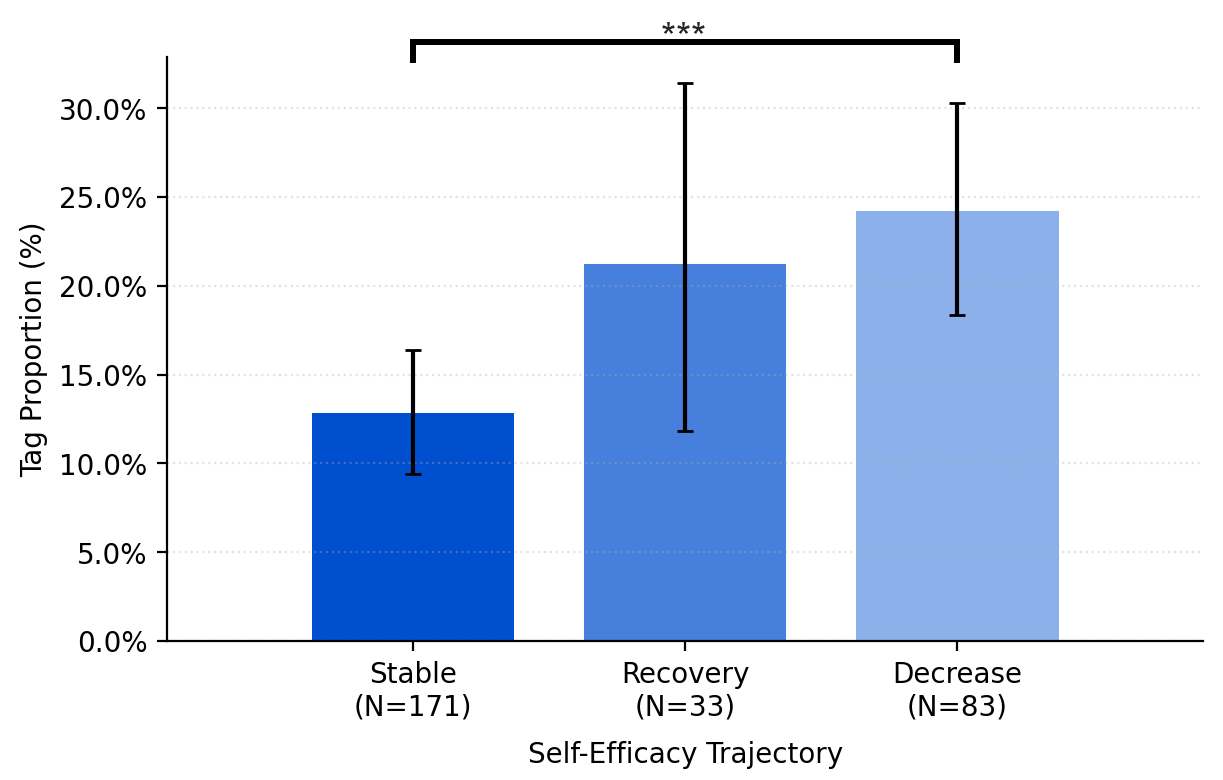
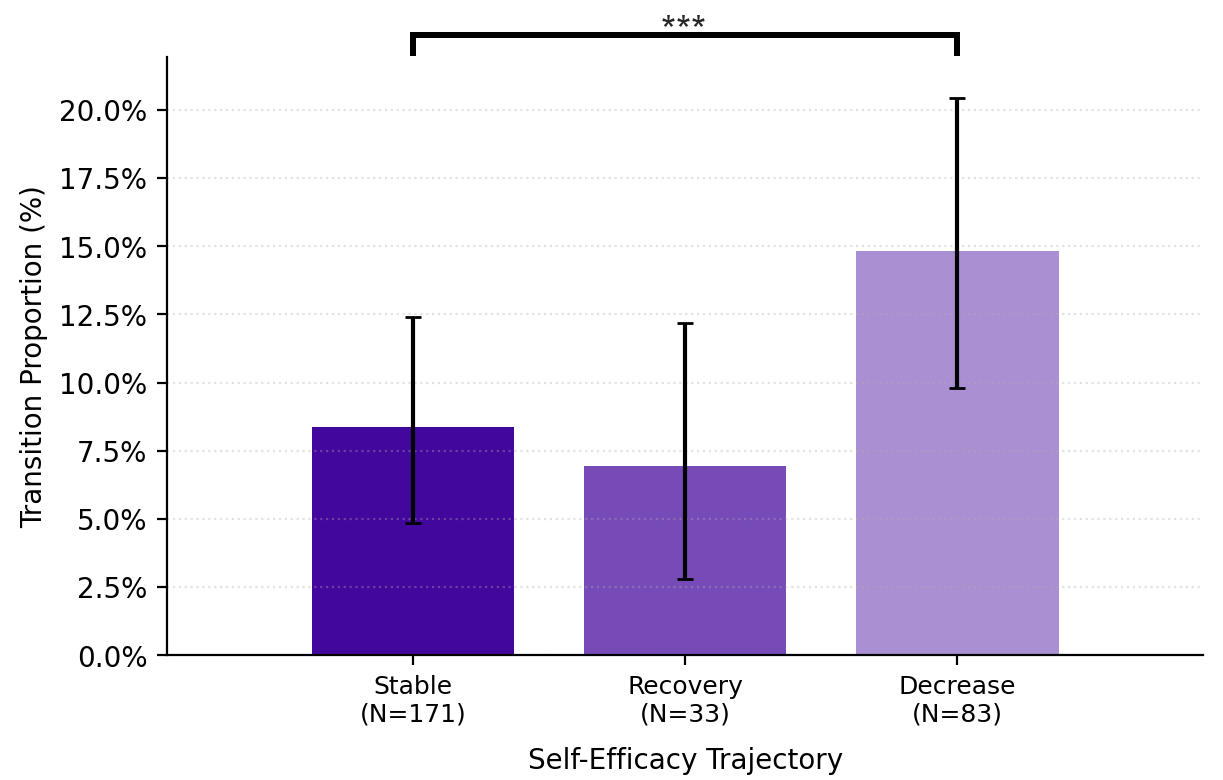
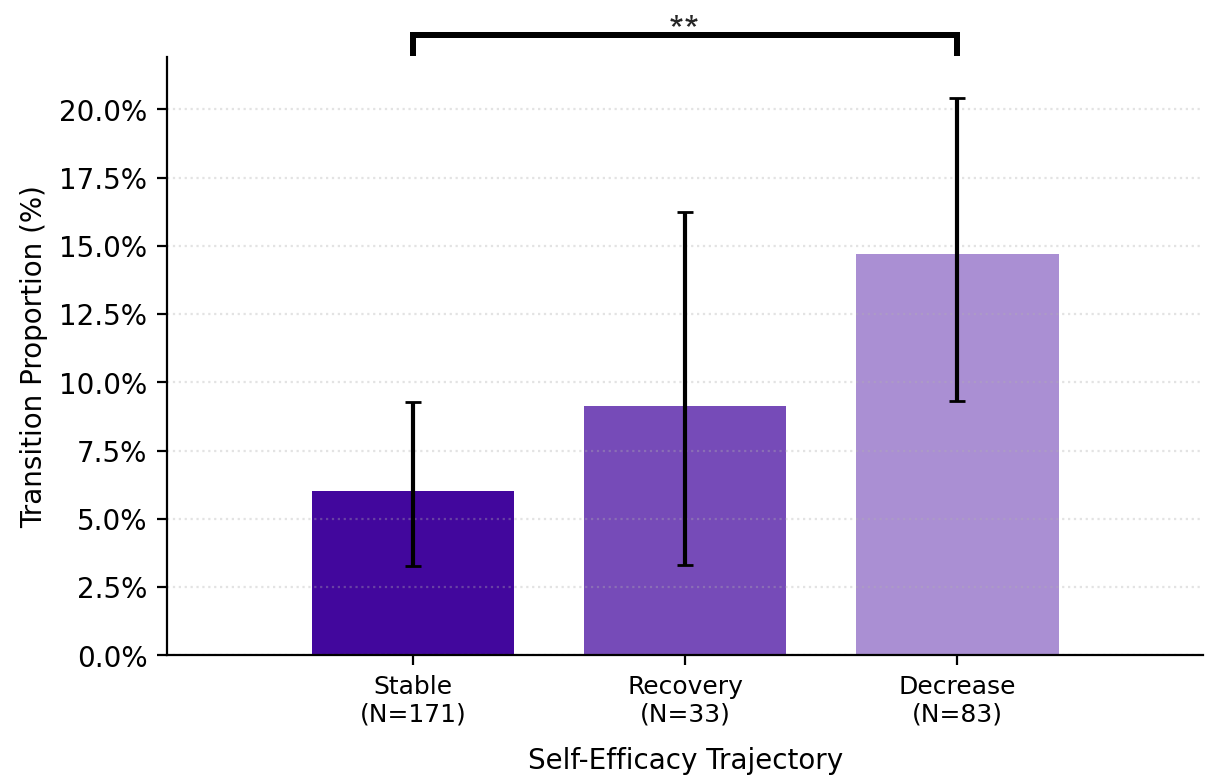
Users with decreasing self-efficacy used significantly more editing prompts. Those who recovered used significantly more reviewing prompts, repositioning the LLM as a critic rather than an editor.
At the transition level, decreasing self-efficacy was marked by repetitive drafting-to-editing and editing-to-editing sequences that progressively handed authorial control to the LLM.
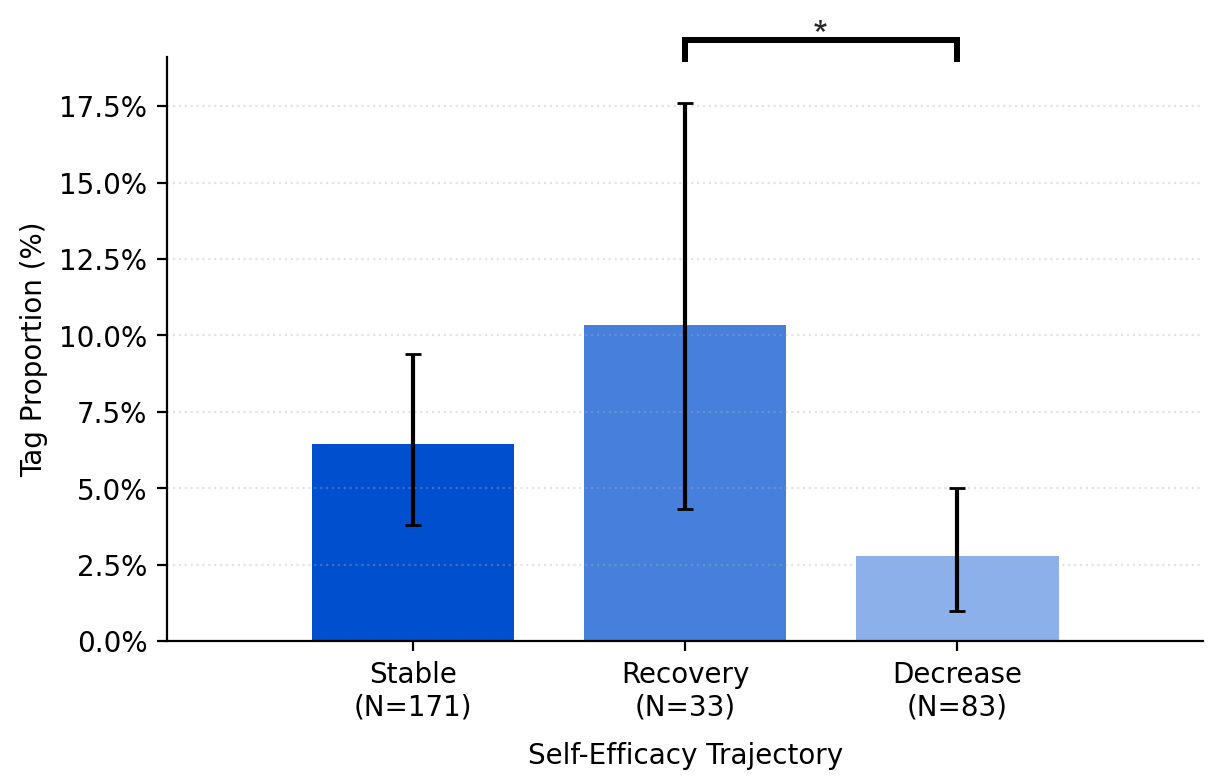
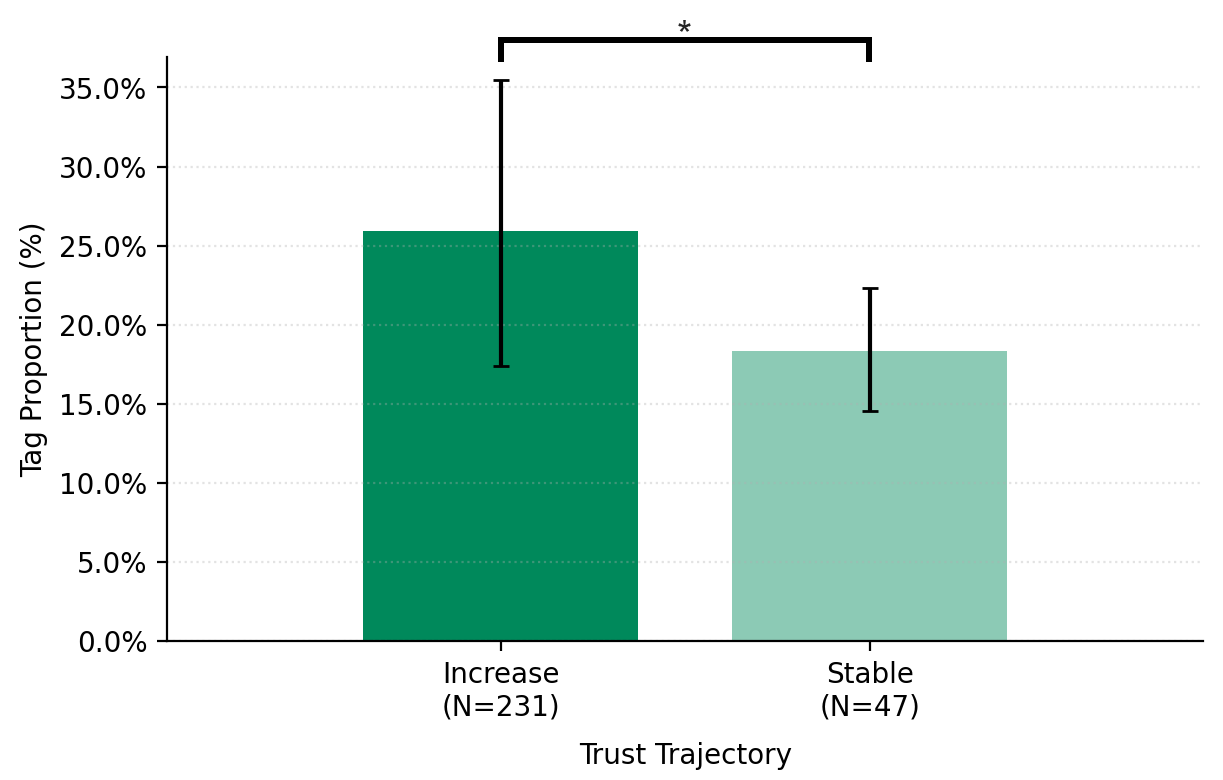
Users who began with lower trust used significantly more information-searching prompts.
✍️ Self-Efficacy Trajectories and Authorship Outcomes
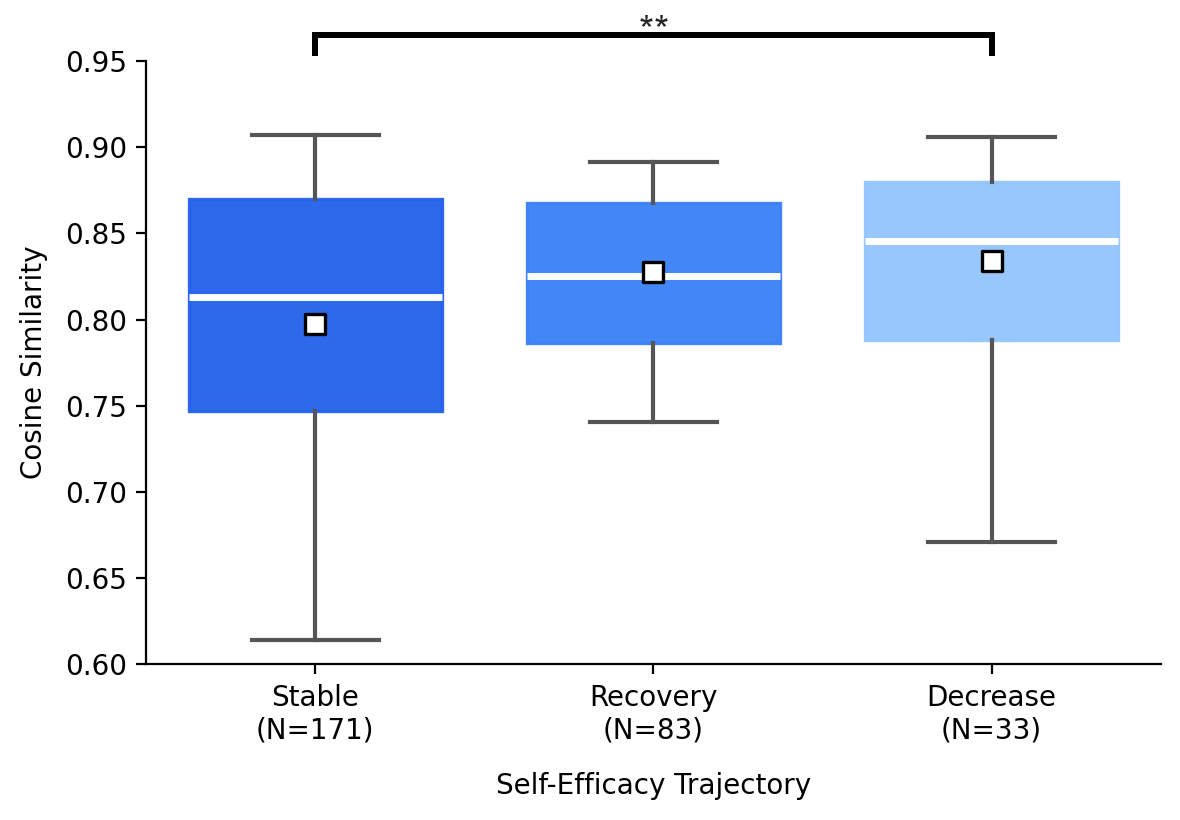
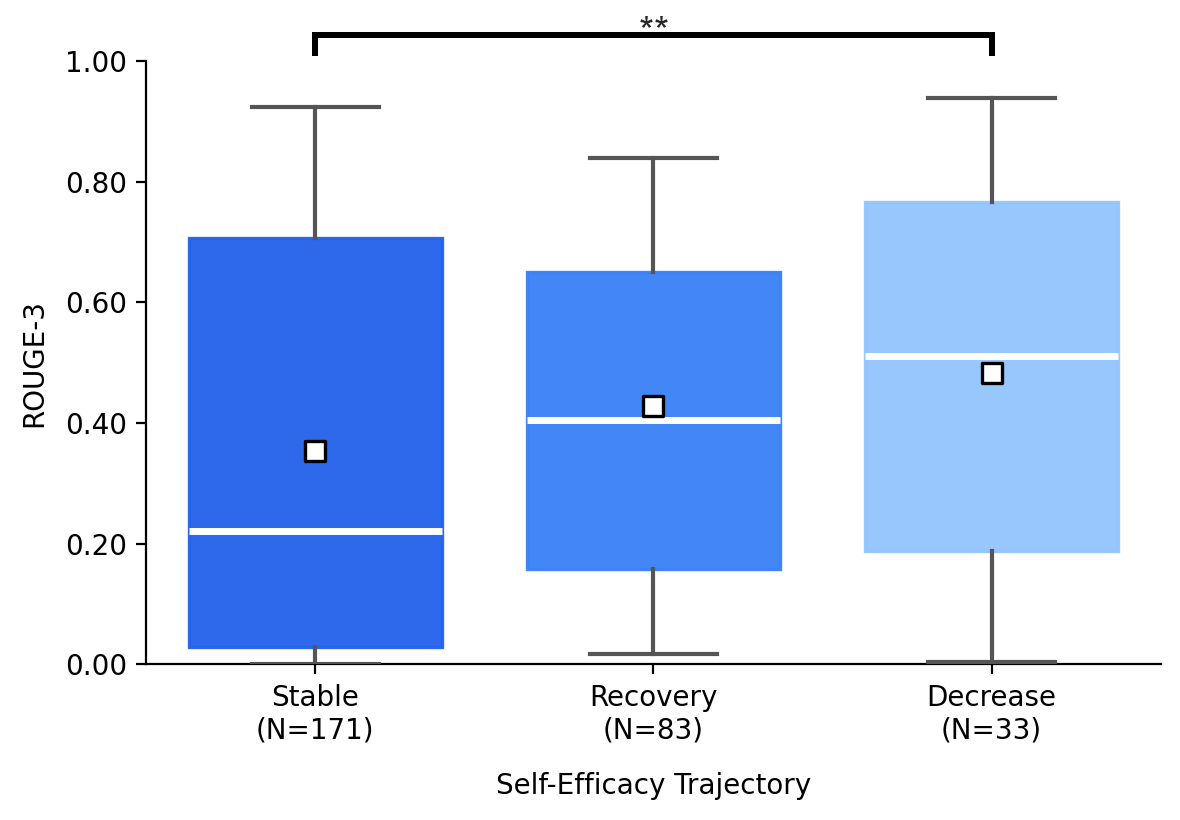
Users with decreasing self-efficacy had significantly greater lexical and semantic overlap with LLM output in their final essays, compared to the stable group.
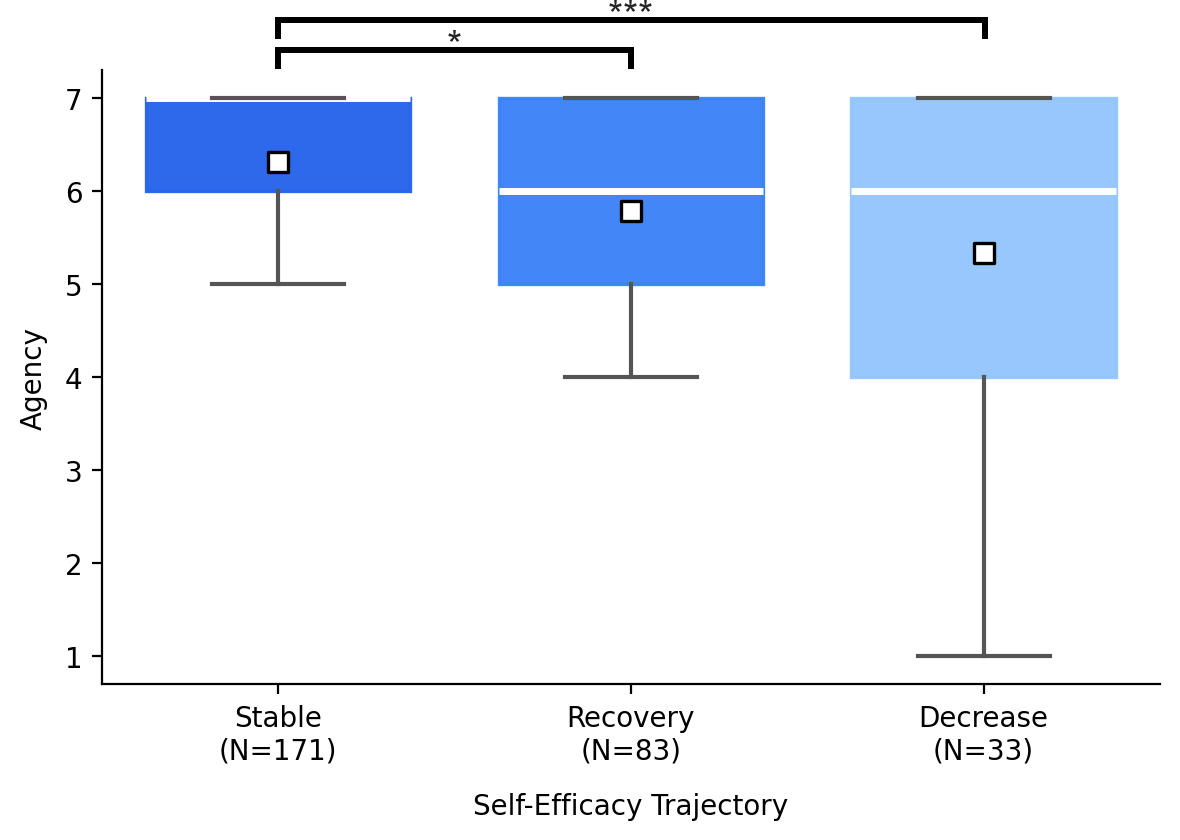
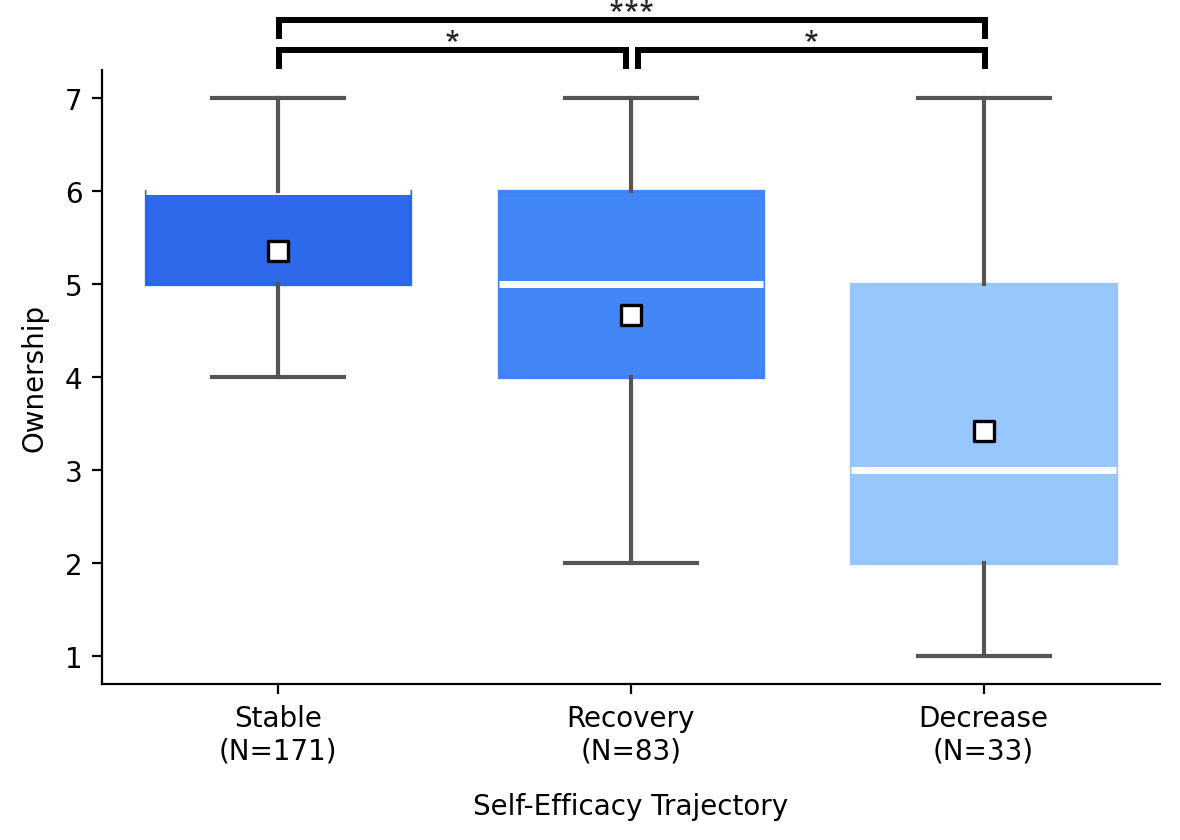
Perceived ownership and agency followed the same hierarchy across all three trajectory groups.
BibTeX
@article{park2026authorship,
title={Authorship Drift: How Self-Efficacy and Trust Evolve During LLM-Assisted Writing},
author={Yeon Su Park and Nadia Azzahra Putri Arvi and Seoyoung Kim and Juho Kim},
year={2026},
eprint={2602.05819},
archivePrefix={arXiv},
primaryClass={cs.HC},
url={https://arxiv.org/abs/2602.05819},
}